Unterschied zwischen Ähnlichkeit und Identität in der Sequenzausrichtung
Der Schlüsselunterschied zwischen Ähnlichkeit und Identität in der Sequenzausrichtung ist das Ähnlichkeit ist die Ähnlichkeit (Ähnlichkeit) zwischen zwei Sequenzen im Vergleich, während Identität die Anzahl der Zeichen ist, die genau zwischen zwei verschiedenen Sequenzen übereinstimmen.
Bioinformatik ist ein interdisziplinäres Wissenschaftsfeld, das hauptsächlich Molekularbiologie und Genetik, Informatik, Mathematik und Statistik umfasst. Die Sequenzausrichtung ist ein wichtiger Begriff in der Bioinformatik. Es ist das Verfahren, bei dem die Sequenzen von DNA, RNA oder Protein angeordnet sind, um Regionen der Ähnlichkeit zu identifizieren, die eine Folge einer funktionellen, strukturellen oder evolutionären Beziehung zwischen den Sequenzen sind. Am Ende der Ausrichtung werden sie als Zeilen innerhalb einer Matrix dargestellt. Um die identischen Zeichen in aufeinanderfolgenden Koloum auszurichten, sind zwischen den Rückständen eingefügte Lücken vorhanden.
INHALT
1. Überblick und wichtiger Unterschied
2. Was ist Ähnlichkeit in der Sequenzausrichtung
3. Was ist Identität in der Sequenzausrichtung
4. Ähnlichkeiten zwischen Ähnlichkeit und Identität in der Sequenzausrichtung
5. Seite für Seitenvergleich - Ähnlichkeit gegenüber Identität in der Sequenzausrichtung in tabellarischer Form
6. Zusammenfassung
Was ist Ähnlichkeit??
Ähnlichkeit in der Sequenzausrichtung ist die Ähnlichkeit zwischen zwei Sequenzen im Vergleich. Diese Tatsache hängt von der Identität von Sequenzen ab. Die Ähnlichkeit zeigt, inwieweit die Rückstände ausgerichtet sind. Daher enthalten ähnliche Sequenzen ähnliche Eigenschaften. In der Bioinformatik ist Ähnlichkeit ein Instrument zur Beurteilung der Ähnlichkeit zwischen zwei Proteinen.
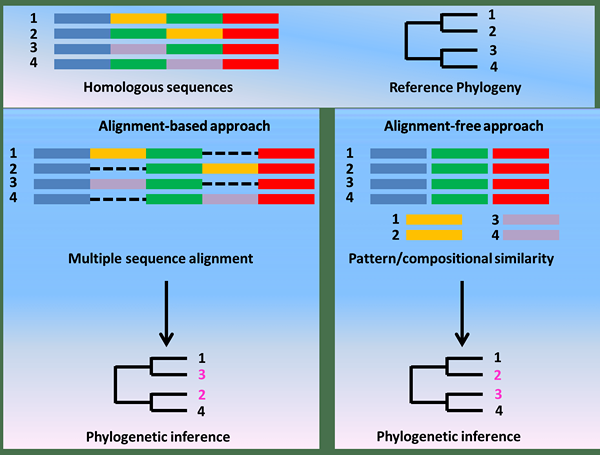
Abbildung 01: Ähnlichkeit in der Sequenzausrichtung
Es gibt zwei Hauptschritte, um den Ausrichtungsprozess für die Sequenz auszurichten. Der erste Schritt ist eine paarweise Ausrichtung, die dazu beiträgt, die optimale Ausrichtung zwischen zwei Sequenzen (einschließlich Lücken) unter Verwendung von Algorithmen wie Explosion, Fasta und Lalign zu finden. Der passende Algorithmus findet die minimale Anzahl von Bearbeitungsvorgängen; In-Del und Substitutionen, um eine Sequenz auf die andere Sequenz auszurichten. Nach der paarweise Ausrichtung ist es notwendig, zwei quantitative Parameter aus jedem Paar-Vergleich zu erhalten. Sie sind Identität und Ähnlichkeit.
Was ist Identität?
Identität in der Sequenzausrichtung ist die Anzahl der Zeichen, die genau zwischen zwei verschiedenen Sequenzen übereinstimmen. Daher zählen Lücken bei der Beurteilung der Identität nicht. Die Messung wird als relational zur kürzeren Sequenz zwischen den beiden Sequenzen angesehen. Es impliziert erheblich, dass es den Effekt hat, bei dem die Sequenzidentität nicht transitiv ist. Wenn x = y und y = z, dann ist x nicht unbedingt gleich Z. Dies wird in Bezug auf die Identitätsabstandsmaßnahme abgeleitet.
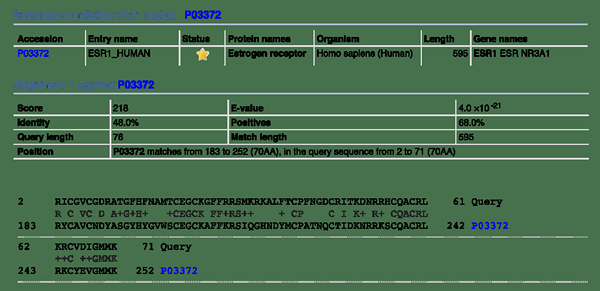
Abbildung 02: Identität in der Sequenzausrichtung
Zum Beispiel hat X eine Sequenz von aaggctt, y eine Sequenz von Aaggc und Z hat eine Sequenz von Aaggcat. Die Identität zwischen x und y ist 100% 5 identische Nukleotide / min [Länge (x), Länge (y)]. Die Identität zwischen y und z beträgt ebenfalls 100%. Die Identität zwischen x und z beträgt jedoch nur 85% (6 identische Nukleotide / 7).
Was sind die Ähnlichkeiten zwischen Ähnlichkeit und Identität in der Sequenzausrichtung?
- Sowohl Ähnlichkeit als auch Identität sind zwei Begriffe, die wir in der Sequenzausrichtung verwenden.
- Außerdem beziehen sie sich auf die Ähnlichkeit zwischen den beiden Sequenzen.
- Darüber hinaus drücken wir sie als prozentualer Wert aus.
Was ist der Unterschied zwischen Ähnlichkeit und Identität in der Sequenzausrichtung?
Die Ähnlichkeit in der Ausrichtung zeigt die Ähnlichkeit zwischen zwei Sequenzen im Vergleich, während die Identität in der Sequenzausrichtung die Menge der Zeichen zeigt, die genau zwischen zwei verschiedenen Sequenzen übereinstimmen. Daher ist dies der Schlüsselunterschied zwischen Ähnlichkeit und Identität in der Sequenzausrichtung.

Zusammenfassung -Ähnlichkeit gegenüber Identität in der Sequenzausrichtung
Die Sequenzausrichtung hilft dabei, Regionen der Ähnlichkeit in DNA, RNA oder Protein aufgrund einer funktionellen, strukturellen oder evolutionären Beziehung zwischen den Sequenzen zu identifizieren. Ähnlichkeit und Identität sind daher zwei Schlüsselbegriffe im Kontext der Sequenzausrichtung. Der Schlüsselunterschied zwischen diesen beiden Begriffen besteht darin, dass Ähnlichkeit die Ähnlichkeit zwischen zwei Sequenzen im Vergleich ist, während Identität die Anzahl der Zeichen ist, die genau zwischen zwei verschiedenen Sequenzen übereinstimmen. Dies ist daher die Zusammenfassung des Unterschieds zwischen Ähnlichkeit und Identität in der Sequenzausrichtung.
Referenz:
1. „Identität und Ähnlichkeit - eine quantitative Maßnahme.Identität und Ähnlichkeit - eine quantitative Maßnahme, die hier verfügbar ist.
2. „Sequenzausrichtung.”Sequenzausrichtung - Bioinformatik.Org Wiki, hier erhältlich.
Bild mit freundlicher Genehmigung:
1. "Ausrichtung basiert und ausgerichtungsfreier Phylogenie" von Kolekar Pandurang - eigene Arbeit (CC von 3.0) über Commons Wikimedia
2. "Blast Sample Output" von Fdardel - eigene Arbeit (CC BY -SA 3.0) über Commons Wikimedia