Unterschied zwischen überwachtem und unbeaufsichtigtem maschinellem Lernen

Schlüsselunterschied - beaufsichtigt vs Unbeaufsichtigt Maschinelles Lernen
Übersichtliches Lernen und unbeaufsichtigtes Lernen sind zwei Kernkonzepte des maschinellen Lernens. Überwachendes Lernen ist eine Aufgabe des maschinellen Lernens, eine Funktion zu lernen, die eine Eingabe an einen Ausgang basiert, der auf den Beispiel-Eingabe-Output-Paaren basiert. Unbeaufsichtigtes Lernen ist die Aufgabe des maschinellen Lernens, eine Funktion zu schließen, um die versteckte Struktur aus unbeschriebenen Daten zu beschreiben. Der Schlüsselunterschied Zwischen beaufsichtigter und unbeaufsichtigtem maschinelles Lernen ist das Überwachendes Lernen verwendet beschriftete Daten, während unbeaufsichtigtes Lernen unbezeichnete Daten verwendet.
Maschinelles Lernen ist ein Bereich in der Informatik, das einem Computersystem aus Daten lernen kann, ohne explizit programmiert zu werden. Es ermöglicht es, die Daten zu analysieren und Muster darin vorherzusagen. Es gibt viele Anwendungen des maschinellen Lernens. Einige von ihnen sind Gesichtserkennung, Gestenerkennung und Spracherkennung. Es gibt verschiedene Algorithmen im Zusammenhang mit maschinellem Lernen. Einige von ihnen sind Regression, Klassifizierung und Clustering. Die häufigsten Programmiersprachen für die Entwicklung von Anwendungen auf maschinelles Lernen sind R und Python. Andere Sprachen wie Java, C ++ und Matlab können ebenfalls verwendet werden.
INHALT
1. Überblick und wichtiger Unterschied
2. Was wird beaufsichtigt? Lernen
3. Was ist unbeaufsichtigtes Lernen
4. Ähnlichkeiten zwischen überwachtem und unbeaufsichtigtem maschinellem Lernen
5. Seite an Seite Vergleich - Überlebte gegen unbeaufsichtigte maschinelles Lernen in tabellarischer Form
6. Zusammenfassung
Was wird beaufsichtigt? Lernen?
In maschinell lernbasierten Systemen funktioniert das Modell nach einem Algorithmus. Im überwachten Lernen wird das Modell überwacht. Zunächst ist es erforderlich, das Modell zu trainieren. Mit dem gewonnenen Wissen kann es Antworten für die zukünftigen Instanzen vorhersagen. Das Modell wird mit einem beschrifteten Datensatz trainiert. Wenn dem System ein Beispieldaten übergeben wird, kann das Ergebnis vorhersagen. Im Folgenden finden Sie einen kleinen Auszug aus dem beliebten Iris -Datensatz.
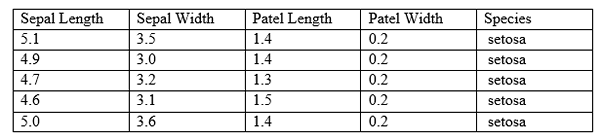
Gemäß der obigen Tabelle werden die Sepallänge, die Sepalbreite, die Patellänge, die Patelbreite und die Arten als Attribute bezeichnet. Die Spalten sind als Funktionen bekannt. Eine Zeile enthält Daten für alle Attribute. Daher wird eine Zeile als Beobachtung bezeichnet. Die Daten können entweder numerisch oder kategorisch sein. Das Modell erhält die Beobachtungen mit dem entsprechenden Speziesamen als Eingabe. Wenn eine neue Beobachtung angegeben wird, sollte das Modell die Art der Arten vorhersagen, zu der sie gehört.
Im überwachten Lernen gibt es Algorithmen zur Klassifizierung und Regression. Die Klassifizierung ist der Prozess der Klassifizierung der gekennzeichneten Daten. Das Modell erstellte Grenzen, die die Datenkategorien trennten. Wenn dem Modell neue Daten zur Verfügung gestellt werden. Die K-Nearest-Nachbarn (KNN) ist ein Klassifizierungsmodell. Abhängig vom K -Wert wird die Kategorie entschieden. Wenn K beispielsweise 5 ist, wenn ein bestimmter Datenpunkt in der Kategorie A und sechs Datenpunkte in Kategorie B nahe acht Datenpunkten liegt, wird der Datenpunkt als a klassifiziert.
Die Regression ist der Prozess der Vorhersage des Trends der vorherigen Daten, um das Ergebnis der neuen Daten vorherzusagen. In der Regression kann der Ausgang aus einer oder mehreren kontinuierlichen Variablen bestehen. Die Vorhersage erfolgt anhand einer Zeile, die die meisten Datenpunkte abdeckt. Das einfachste Regressionsmodell ist eine lineare Regression. Es ist schnell und erfordert keine Tuning -Parameter wie in KNN. Wenn die Daten einen parabolischen Trend zeigen, ist das lineare Regressionsmodell nicht geeignet.
Das sind einige Beispiele für überwachte Lernalgorithmen. Im Allgemeinen sind die aus beaufsichtigten Lernmethoden generierten Ergebnisse genauer und zuverlässiger, da die Eingabedaten bekannt und gekennzeichnet sind. Daher muss die Maschine nur die verborgenen Muster analysieren.
Was ist unbeaufsichtigtes Lernen?
Im unbeaufsichtigten Lernen wird das Modell nicht beaufsichtigt. Das Modell wirkt selbst, um die Ergebnisse vorherzusagen. Es verwendet Algorithmen für maschinelles Lernen, um zu Schlussfolgerungen zu unbezeichneten Daten zu kommen. Im Allgemeinen sind die unbeaufsichtigten Lernalgorithmen schwieriger als überwachte Lernalgorithmen, da es nur wenige Informationen gibt. Clustering ist eine Art unbeaufsichtigtes Lernen. Es kann verwendet werden, um die unbekannten Daten mithilfe von Algorithmen zu gruppieren. Das K-Mittel- und Dichte-basierte Clustering sind zwei Clustering-Algorithmen.
K-Mean-Algorithmus, platziert K Centroid zufällig für jeden Cluster. Dann wird jeder Datenpunkt dem nächstgelegenen Schwerpunkt zugewiesen. Die euklidische Entfernung wird verwendet, um den Abstand vom Datenpunkt zum Schwerpunkt zu berechnen. Die Datenpunkte werden in Gruppen eingeteilt. Die Positionen für K -Zentroide werden erneut berechnet. Die neue Schwerpunktposition wird durch den Mittelwert aller Punkte in der Gruppe bestimmt. Wieder wird jeder Datenpunkt dem nächstgelegenen Schwerpunkt zugewiesen. Dieser Vorgang wiederholt sich, bis sich die Schwerpunkte nicht mehr ändern. K-Mean ist ein schneller Clustering-Algorithmus, aber es gibt keine spezifizierte Initialisierung von Clustering-Punkten. Außerdem gibt es eine hohe Variation von Clustering -Modellen basierend auf der Initialisierung von Clusterpunkten.
Ein weiterer Clustering -Algorithmus ist Dichte basierte Clusterbildung. Es ist auch als dichte basierte räumliche Clustering -Anwendungen mit Rauschen bekannt. Es funktioniert, indem es einen Cluster als maximale Satz von Dichte mit verbundenen Punkten definiert. Sie sind zwei Parameter, die für dichte basierte Clusterbildung verwendet werden. Sie sind ɛ (Epsilon) und Mindestpunkte. Das ɛ ist der maximale Radius der Nachbarschaft. Die Mindestpunkte sind die minimale Anzahl von Punkten in der Nachbarschaft ɛ, um einen Cluster zu definieren. Dies sind einige Beispiele für Clustering, die in unbeaufsichtigtes Lernen fallen.
Im Allgemeinen sind die Ergebnisse, die aus unbeaufsichtigten Lernalgorithmen erzeugt werden.
Was ist die Ähnlichkeit zwischen überwachtem und unbeaufsichtigtem maschinellem Lernen?
- Sowohl überwacht als auch unbeaufsichtigtes Lernen sind Arten des maschinellen Lernens.
Was ist der Unterschied zwischen überwachtem und unbeaufsichtigtem maschinellem Lernen?
Beaufsichtigt gegen unbeaufsichtigtes maschinelles Lernen | |
| Überwachendes Lernen ist die Aufgabe des maschinellen Lernens, eine Funktion zu lernen, die eine Eingabe an einen Ausgang basiert, der auf Beispielprotokollpaaren basiert. | Unüberständiges Lernen ist die Aufgabe des maschinellen Lernens, eine Funktion zu schließen, um die versteckte Struktur aus unbezeichneten Daten zu beschreiben. |
| Hauptfunktionalität | |
| Im überwachten Lernen sagt das Modell das Ergebnis an, das auf den markierten Eingabedaten basiert. | Im unbeaufsichtigten Lernen prognostiziert das Modell das Ergebnis ohne markierte Daten, indem die Muster selbst identifiziert werden. |
| Genauigkeit der Ergebnisse | |
| Die Ergebnisse, die aus überwachten Lernmethoden generiert werden, sind genauer und zuverlässiger. | Die Ergebnisse, die aus unbeaufsichtigten Lernmethoden erzeugt werden, sind nicht viel genau und zuverlässig. |
| Hauptalgorithmen | |
| Es gibt Algorithmen zur Regression und Klassifizierung im überwachten Lernen. | Es gibt Algorithmen zum Clustering beim unbeaufsichtigten Lernen. |
Zusammenfassung -überwacht vs Unbeaufsichtigt Maschinelles Lernen
Übersichtliches Lernen und unbeaufsichtigtes Lernen sind zwei Arten des maschinellen Lernens. Überwachendes Lernen ist die Aufgabe des maschinellen Lernens, eine Funktion zu lernen, die eine Eingabe an einen Ausgang basiert, der auf Beispielprotokollpaaren basiert. Unüberständiges Lernen ist die Aufgabe des maschinellen Lernens, eine Funktion zu schließen, um die versteckte Struktur aus unbezeichneten Daten zu beschreiben. Der Unterschied zwischen überwachtem und unbeaufsichtigtem maschinell.
Referenz:
1.Thebigdatauniversität. Maschinelles Lernen - überwacht gegen unbeaufsichtigtes Lernen, kognitive Klasse, 13. März. 2017. Hier verfügbar
2."Unbeaufsichtigtes Lernen.Wikipedia, Wikimedia Foundation, 20. März. 2018. Hier verfügbar
3."Überwachtes Lernen.Wikipedia, Wikimedia Foundation, 15. März. 2018. Hier verfügbar
Bild mit freundlicher Genehmigung:
1.'2729781' von GDJ (Public Domain) über Pixabay