Unterschied zwischen Clustering und Klassifizierung
Der Schlüsselunterschied Zwischen Clustering und Klassifizierung ist das Clustering ist eine unbeaufsichtigte Lerntechnik, die ähnliche Instanzen auf der Grundlage von Merkmalen gruppiert, während die Klassifizierung eine überwachte Lerntechnik ist, die vordefinierte Tags den Instanzen auf der Grundlage von Merkmalen zugewiesen wird.
Obwohl Clustering und Klassifizierung ähnliche Prozesse zu sein scheinen, gibt es einen Unterschied zwischen ihnen, basierend auf ihrer Bedeutung. In der Data Mining World sind Clustering und Klassifizierung zwei Arten von Lernmethoden. Beide Methoden charakterisieren Objekte nach einem oder mehreren Merkmalen in Gruppen.
INHALT
1. Überblick und wichtiger Unterschied
2. Was ist Clustering
3. Was ist Klassifizierung
4. Seite für Seitenvergleich - Clustering vs -Klassifizierung in tabellarischer Form
5. Zusammenfassung
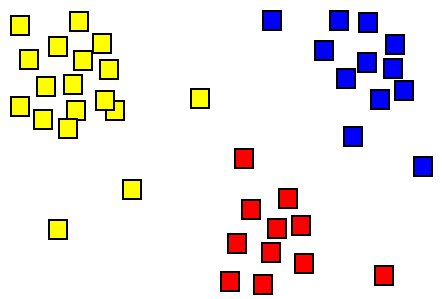
Was ist Clustering?
Clustering ist eine Methode, um Objekte so zu gruppieren. Es ist eine gemeinsame Technik für die statistische Datenanalyse für maschinelles Lernen und Data Mining. Die explorative Datenanalyse und -verallgemeinerung ist auch ein Bereich, der Clustering verwendet.
Abbildung 01: Clustering
Das Clustering gehört zum unbeaufsichtigten Data Mining. Es ist kein einzelner spezifischer Algorithmus, aber es ist eine allgemeine Methode, um eine Aufgabe zu lösen. Daher ist es möglich, ein Clustering mit verschiedenen Algorithmen zu erreichen. Der entsprechende Cluster -Algorithmus- und Parametereinstellungen hängt von den einzelnen Datensätzen ab. Es ist keine automatische Aufgabe, aber ein iterativer Entdeckungsprozess. Daher ist es erforderlich, die Datenverarbeitung und Parametermodellierung zu ändern, bis das Ergebnis die gewünschten Eigenschaften erreicht. K-Means-Clustering und hierarchische Clusterbildung sind zwei gemeinsame Clustering-Algorithmen im Data Mining.
Was ist Klassifizierung?
Die Klassifizierung ist ein Kategorisierungsprozess, der einen Trainingssatz von Daten verwendet, um Objekte zu erkennen, zu differenzieren und zu verstehen. Die Klassifizierung ist eine überwachte Lerntechnik, bei der ein Trainingssatz und korrekt definierte Beobachtungen verfügbar sind.
Abbildung 02: Klassifizierung
Der Algorithmus, der Klassifizierung implementiert, ist der Klassifikator, während die Beobachtungen die Instanzen sind. K-nearest Nachbaralgorithmus und Entscheidungsbaumalgorithmen sind die berühmtesten Klassifizierungsalgorithmen im Data Mining.
Was ist der Unterschied zwischen Clustering und Klassifizierung?
Clustering ist unbeaufsichtigtes Lernen, während die Klassifizierung eine überwachte Lerntechnik ist. Es gruppiert ähnliche Instanzen auf der Grundlage von Merkmalen, während die Klassifizierung vordefinierte Tags an Instanzen auf der Grundlage von Merkmalen zuweist. Clustering Teilen Sie den Datensatz in Teilmengen auf, um die Instanzen mit ähnlichen Funktionen zu gruppieren. Es wird weder beschriftete Daten noch ein Trainingssatz verwendet. Andererseits kategorisieren Sie die neuen Daten gemäß den Beobachtungen des Trainingssatzes. Das Trainingssatz ist beschriftet.
Das Ziel der Clusterbildung ist es, eine Reihe von Objekten zu gruppieren, um festzustellen, ob es eine Beziehung zwischen ihnen gibt, während die Klassifizierung feststellt.
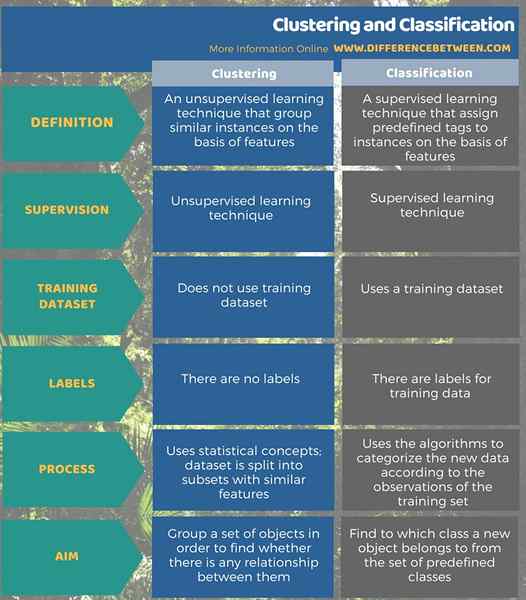
Zusammenfassung -Clustering gegen Klassifizierung
Clustering und Klassifizierung können ähnlich erscheinen, da beide Data -Mining -Algorithmen den Datensatz in Teilmengen unterteilen, aber zwei verschiedene Lerntechniken im Data Mining sind, um zuverlässige Informationen aus einer Sammlung von Rohdaten zu erhalten. Der Unterschied zwischen Clustering und Klassifizierung besteht darin, dass Clustering eine unbeaufsichtigte Lerntechnik ist, die ähnliche Instanzen auf der Grundlage von Merkmalen gruppiert, während die Klassifizierung eine überwachte Lerntechnik ist, die vordefinierte Tags den Instanzen auf der Grundlage von Merkmalen zuweist.
Bild mit freundlicher Genehmigung:
1."Cluster-2" von Cluster-2.GIF: Hölle Derivative Arbeit: (gemeinfrei) über Wikimedia Commons 2."Magnetismus" von John Ustiert - Eigene Arbeit. (Public Domain) über Wikimedia Commons